Adversary Simulation with Voice Cloning in Real Time, Part 2
In our first blog post on this series, we discussed the limitations of existing voice changing tools and how AI is changing the face of social engineering attacks. In this post, we detail how to set up of Respeecher and integrate it with Google Voice to achieve seamless real-time voice switching on a live call.
Respeecher Functional Overview
Respeecher’s proprietary technology combine conventional digital signal processing algorithms with optimized deep generative modeling techniques to clone voices. The cloned voices can capture human emotion and nuances and are difficult to distinguish from the original voice. Respeecher offers a speech-to-speech service which provides the ability to emphasize realism, render unknown words and abbreviations, and “works solely in the acoustic domain”.
RTC Demo Instance Options Overview
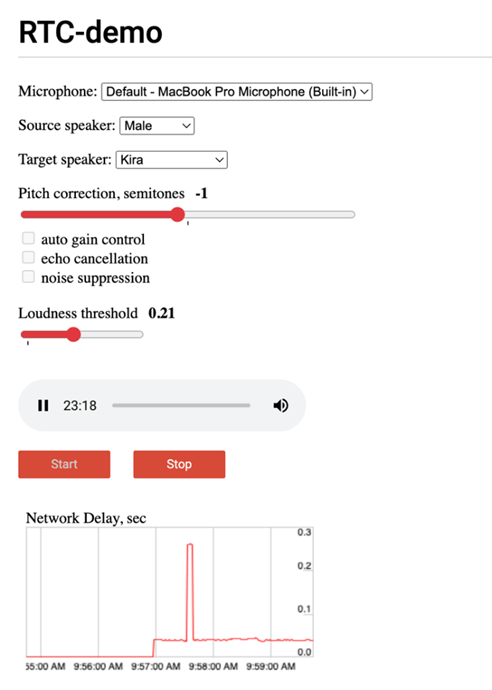
Options:
Microphone:
The microphone is the input, in this example, we are just using the default microphone built into the system.
Source Speaker:
With this option, one can choose the speaker’s gender or have a trained model for the speaker’s voice. For example, it could have my voice trained in as the speaker and the results would be the most realistic.
Pitch Correction in Semitones:
This helps correct a voice so that it doesn’t sound either too low or too high. This is used to correct the pitch since target speakers have different range of voices. Everyone has a different vocal range with the following being the different ranges. For reference, here is the spectrum of where different voice ranges exist. One can use the pitch corrections to shift their range to another, either with their own voice or a cloned voice.
- Soprano: the highest female voice, being able to sing C4 (middle C) to C6 (high C), and possibly higher.
- Mezzo-soprano: a female voice between A3 (A below middle C) and A5 (2nd A above middle C).
- Contralto: the lowest female voice, F3 (F below middle C) to E5 (2nd E above Middle C). Rare contraltos possess a range similar to the tenor.
- Tenor: the highest male voice, B2 (second B below middle C) to A4 (A above middle C), and possibly higher.
- Baritone: a male voice, G2 (two Gs below middle C) to F4 (F above middle C).
- Bass: the lowest male voice, E2 (two Es below middle C) to E4 (the E above middle C).
One can use the pitch corrections to shift their range to another, either with their own voice or a cloned voice.
Target Speaker:
The voice that is cloned. There are other options such as gain control, echo cancellation and noise suppression that were left unchecked as doing so provided optimal results in our test cases.
Loudness Threshold:
This option would allow input in terms of “loudness”. Setting it lower would allow for a tighter sound and setting it higher would cause stuttering as more sound is allowed in.
Lastly, there is the Start and Stop option which will start and stop the voice cloning. To start cloning, simply choose the source speaker/gender and then choose the target speaker. Start at 0 threshold and 0 pitch correction. If the target speaker is a male and the source speaker is a male, it is unlikely that pitch correction will be necessary, although deviating within + or – 1 semitone may give a more realistic result. If the target speaker is a female, this voice cloning technology does a superior job at cloning the voice without any pitch correction with no voice acting necessary from the source speaker.
Latency Graph:
Upon starting the voice cloning, there is a graph that will show the latency between the network and input. As the graph spikes up, there will be noticeable stutters in the output.
Making Calls with Respeecher
Being able to test the demonstration as a proof-of-concept was neat, but ultimately not enough for us to perform a real social engineering call. Usually, an operator will use their mobile phone to make calls using a disposable number or service, called a burner. The issue is that burner phone apps or services don’t have voice cloning implemented in them, (hey—there’s an idea for a product!) so we needed to find a way to route this RTC demo into a burner number and then spoof the number.
For audio routing, we set up a Google Chrome instance with the voice cloning RTC-Demo in a single tab. Our end goal was to use Google Voice as a VoIP number, routing the audio from the voice cloning app into Google Voice. We then used Google Voice to dial in to SpoofCard for number spoofing.
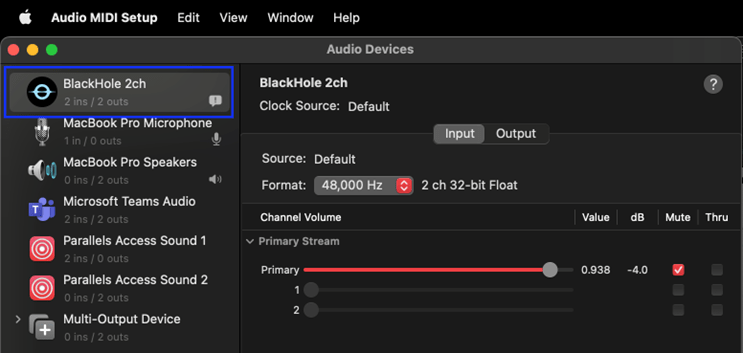
We then used BlackHole, which, in their words, is “a virtual audio driver that allows applications to pass audio to other applications with zero latency”. To configure Blackhole on MacOS make sure you have the BlackHole2ch virtual device added. If not, you can make add an additional device for this. We are using Audio MIDI Setup application on the Mac to verify that BlackHole is working.
Once this is set up, we moved on to Audio Hijack. Audio Hijack is used in tandem with BlackHole to capture audio from the microphone and then send it to another application. For the first 10 minutes, Audio Hijack is free. After 10 minutes, noise will be overlaid. It is possible to restart the 10 minutes by starting and stopping the overlay. The only way to prevent this from happening is either 1.) pay for the software ($64) or 2.) keep social engineering calls less than 10 minutes.
For this set up, I had Google Voice in a private Firefox tab and have Audio Hijack set up to route to the BlackHole output device. Drag the application block over to the left side and select Google Chrome and then drag the Output Device over with the BlackHole 2ch.
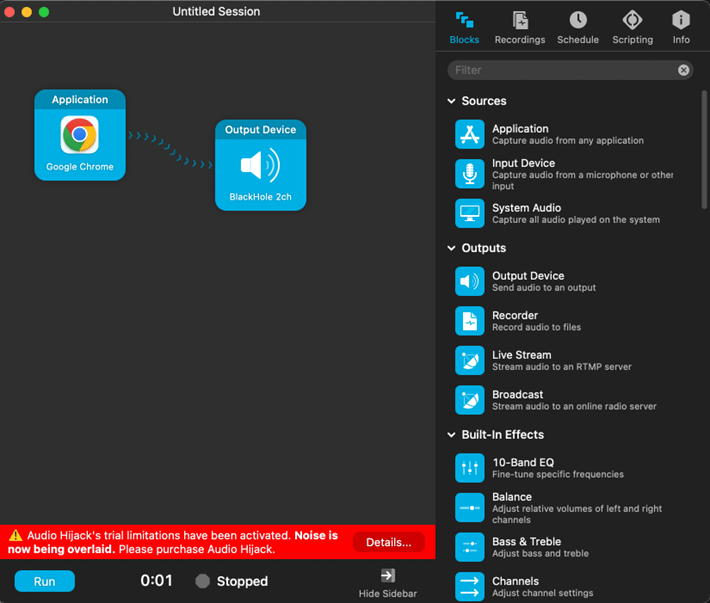
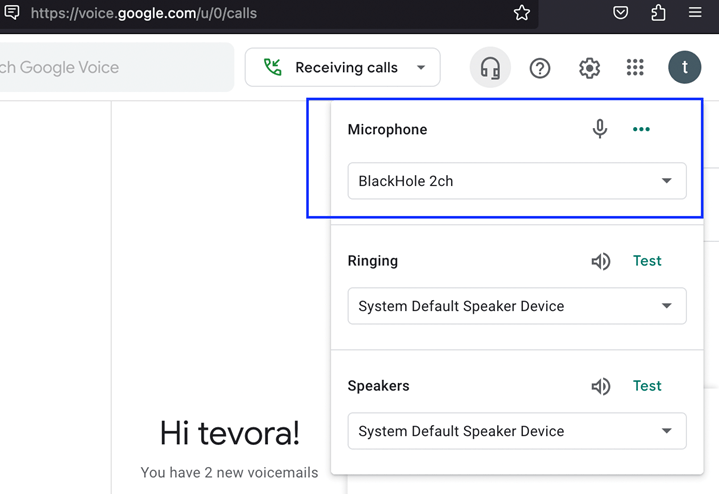
On your Firefox browser, login to Google Voice and ensure that the microphone is also the BlackHole 2ch. Press the headphones button to manage your audio devices for Google Voice.
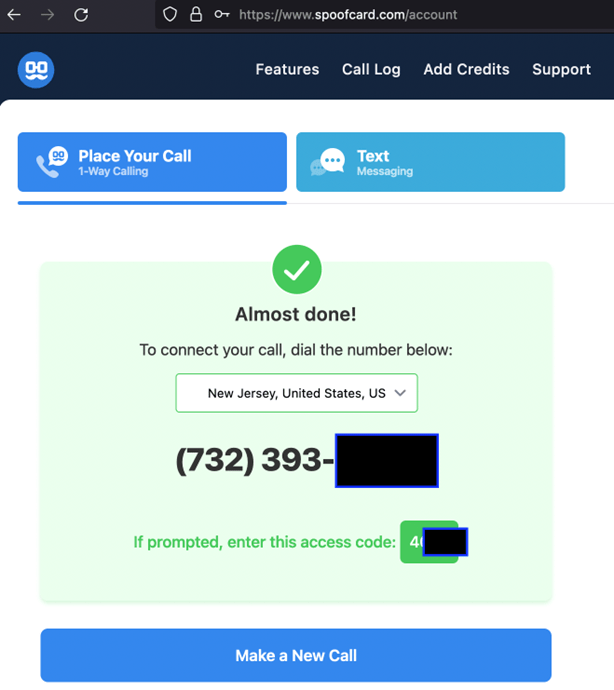
To spoof the number, go to your Spoofcard account from the browser and there will be a dial in number and access code provided after you’ve set the number to spoof and target number.
After chaining Spoofcard into the call, you will now be able to speak with a cloned voice with 0 additional latency through Google Voice through a spoofed number.
The team at Respeecher will train a voice to clone for security assessments if there is permission from the target speaker. This means for adversary simulation type engagements; a client’s voice may be considered in scope for cloning, as discussed in Part 1 of this blog series.
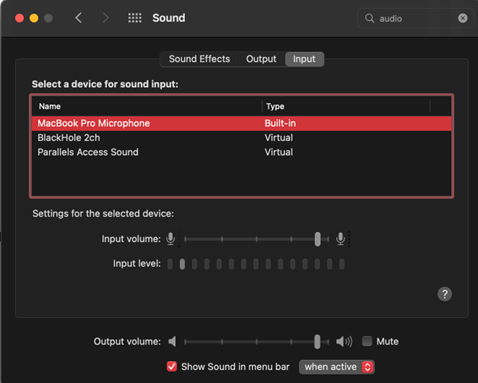
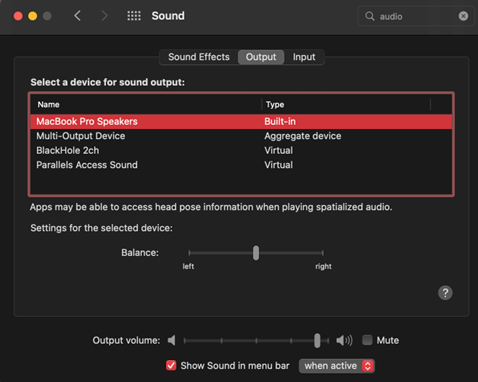
Troubleshooting tips: The biggest issue we had while troubleshooting was no input or output audio after chaining these options together. In MacOS, make sure the Sound Preferences have the correct Output and Input.